Week 2 [Mon, Jan 16th] - Topics
Guidance for the item(s) below:
As you know, OOP is a core part of this module. Let's start learning the OOP paradigm this week.
Guidance for the item(s) below:
Now that you know what objects are, let's see how they are used in Java, which happens to be an OOP language.
Guidance for the item(s) below:
Having seen how to use objects in Java, the next step is learn how to define new kinds of objects (aka classes) in Java.
Guidance for the item(s) below:
Now that we know about classes, let's learn what class-level members are and how to use them in Java.
Guidance for the item(s) below:
You are going to start your project pretty soon. As you are adding feature increments to your project, you'll need a way to keep track of all those changes too. The tool we are going to use for that is called Git.
Let's jump in and learn how to get started using Git in your own computer.
Guidance for the item(s) below:
Guidance for the item(s) below:
Now that we know what RCS is in general, we can try to practice it ourselves using a specific tool i.e., Git.
The following section gives a specific scenario that includes the steps of initializing a Git repository.
If you are new to Git, you are highly recommended to follow those steps in your own computer to get some hands-on practice as you learn Git usage.
Can create a local Git repo
Let's take your first few steps in your Git (with GitHub) journey.
0. Take a peek at the full picture(?). Optionally, if you are the sort who prefers to have some sense of the full picture before you get into the nitty-gritty details, watch the video in the panel below:
1. The first step is to install SourceTree, which is Git + a GUI for Git. If you prefer to use Git via the command line (i.e., without a GUI), you can install Git instead.
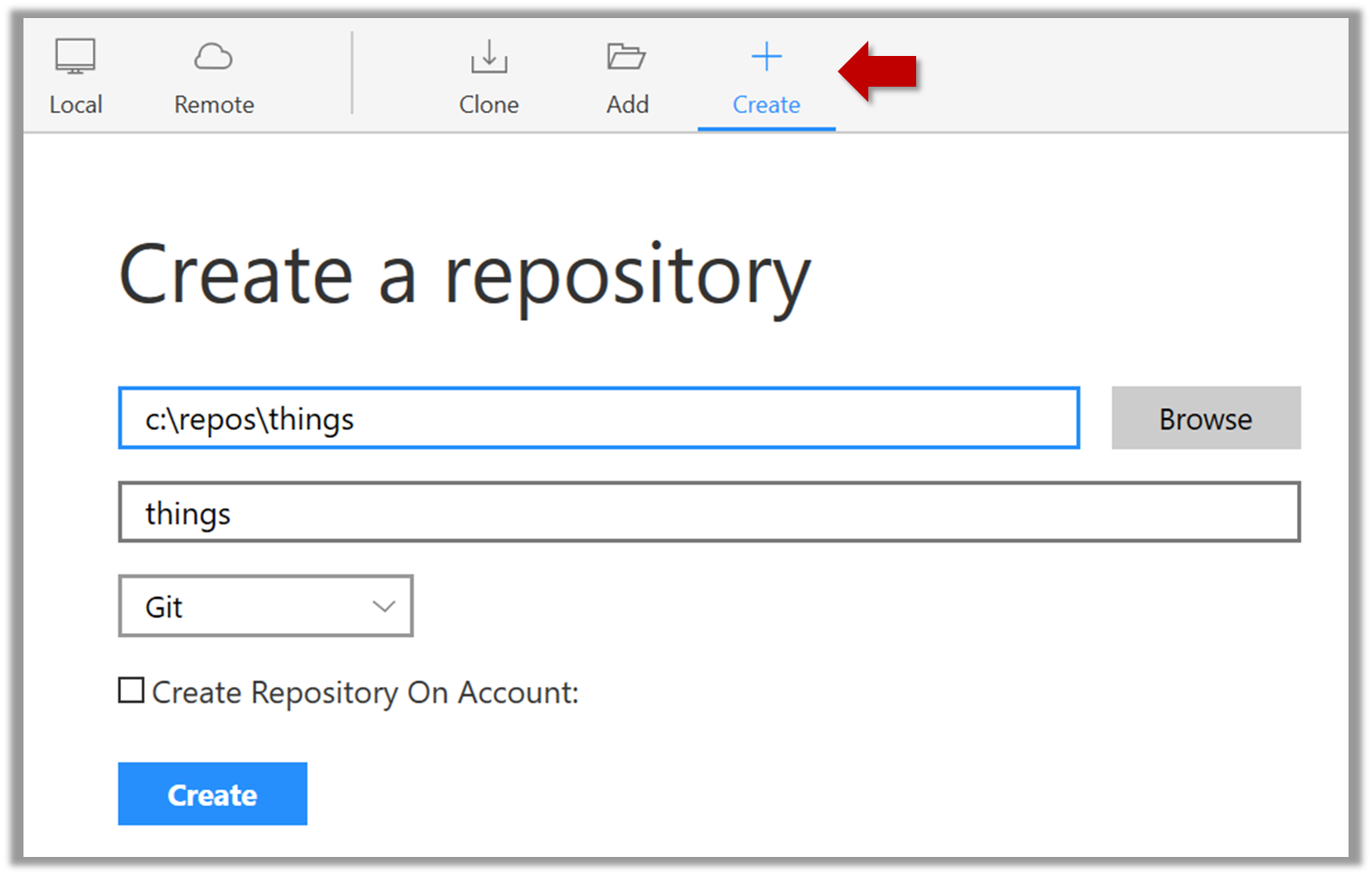
2. Next, initialize a repository. Let us assume you want to version control content in a specific directory. In that case, you need to initialize a Git repository in that directory. Here are the steps:
Create a directory for the repo (e.g., a directory named things).
Windows: Click File → Clone/New…. Click on Create button.
Mac: New... → Create New Repository.
Enter the location of the directory (Windows version shown below) and click Create.
Go to the things folder and observe how a hidden folder .git has been created.
Windows: you might have to configure Windows Explorer to show hidden files.
Open a Git Bash Terminal.
If you installed SourceTree, you can click the Terminal button to open a GitBash terminal.
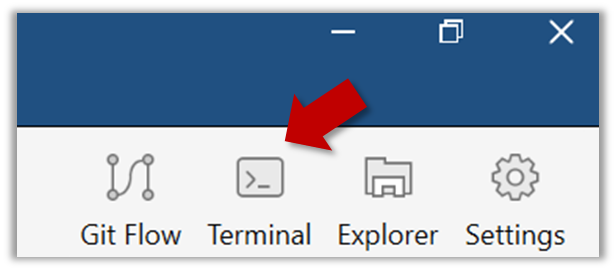
Navigate to the things directory.
Use the command git init which should initialize the repo.
$ git init
Initialized empty Git repository in c:/repos/things/.git/
You can use the command ls -a to view all files, which should show the .git directory that was created by the previous command.
$ ls -a
. .. .git
You can also use the git status command to check the status of the newly-created repo. It should respond with something like the following:
git status
# On branch master
#
# Initial commit
#
nothing to commit (create/copy files and use "git add" to track)
As you see above, this textbook explains how to use Git via SourceTree (a GUI client) as well as via the Git CLI. If you are new to Git, we recommend you learn both the GUI method and the CLI method -- The GUI method will help you visualize the result better while the CLI method is more universal (i.e., you will not be tied to any GUI) and more flexible/powerful.
If you are new to Git, we caution you against using Git or GitHub features that come with the IDE as it is better to learn Git independent of any other tool. Similarly, using clients provided by GitHub (e.g., GitHub Desktop GUI client) will make it harder for you to separate Git features from GitHub features.
Guidance for the item(s) below:
For the next few sections, the drill is the same: first learn the high-level explanation of a revision control concept, and then follow the given scenarios yourself to learn how to apply that concept using Git.
Can commit using Git
After initializing a repository, Git can help you with revision controlling files inside the working directory. However, it is not automatic. It is up to you to tell Git which of your changes (aka revisions) should be committed to its memory for later use. Saving changes into Git's memory in that way is often called committing and a change saved to the revision history is called a commit.
Working directory: the root directory revision-controlled by Git (e.g., the directory in which the repo was initialized).
Commit (noun): a change (aka a revision) saved in the Git revision history.
(verb): the act of creating a commit i.e., saving a change in the working directory into the Git revision history.
Here are the steps you can follow to learn how to work with Git commits:
1. Do some changes to the content inside the working directory e.g., create a file named fruits.txt in the things directory and add some dummy text to it.
2. Observe how the file is detected by Git.
The file is shown as ‘unstaged’.
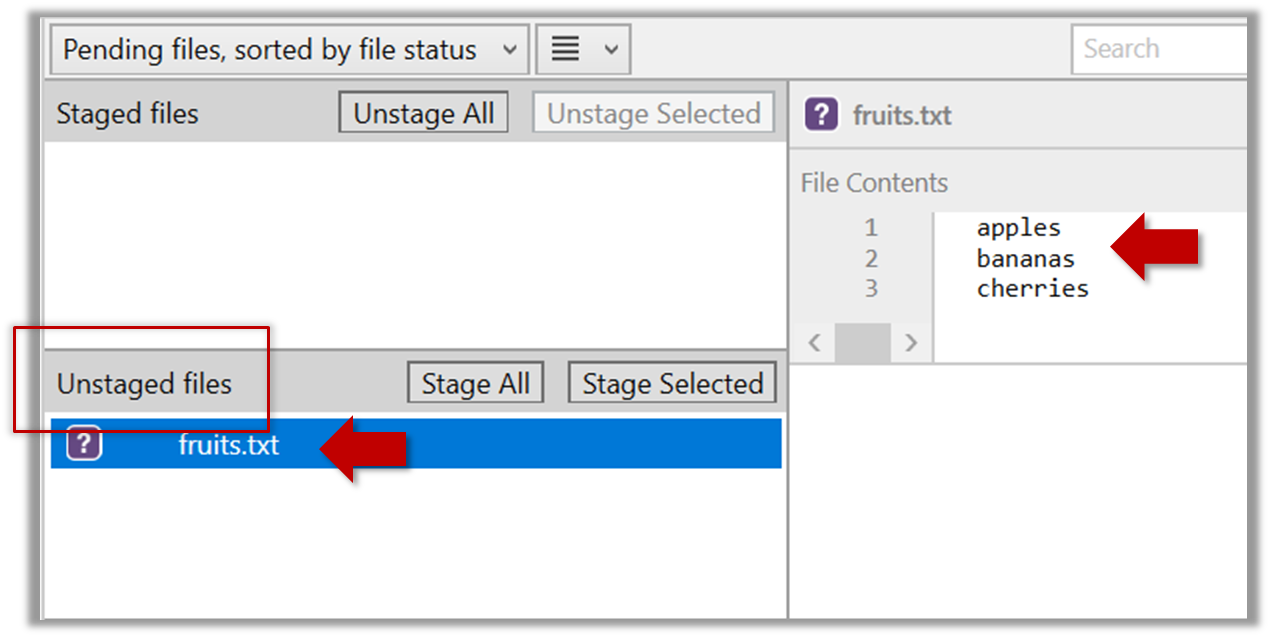
You can use the git status command to check the status of the working directory.
git status
# On branch master
#
# Initial commit
#
# Untracked files:
# (use "git add <file>..." to include in what will be committed)
#
# a.txt
nothing added to commit but untracked files present (use "git add" to track)
3. Stage the changes to commit: Although Git has detected the file in the working directory, it will not do anything with the file unless you tell it to. Suppose you want to commit the current changes to the file. First, you should stage the file.
Stage (verb): Instructing Git to prepare a file for committing.
Select the fruits.txt and click on the Stage Selected button.
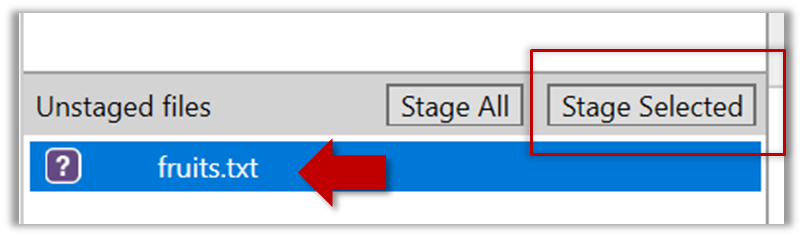
fruits.txt should appear in the Staged files panel now.
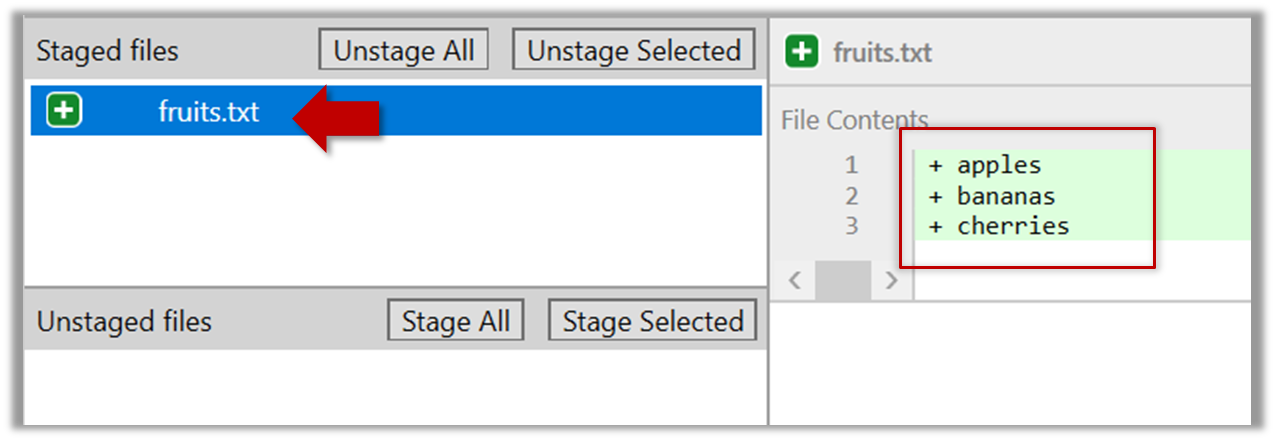
You can use the stage or the add command (they are synonyms, add is the more popular choice) to stage files.
git add fruits.txt
git status
# On branch master
#
# Initial commit
#
# Changes to be committed:
# (use "git rm --cached <file>..." to unstage)
#
# new file: fruits.txt
#
4. Commit the staged version of fruits.txt.
Click the Commit button, enter a commit message e.g. add fruits.txt into the text box, and click Commit.
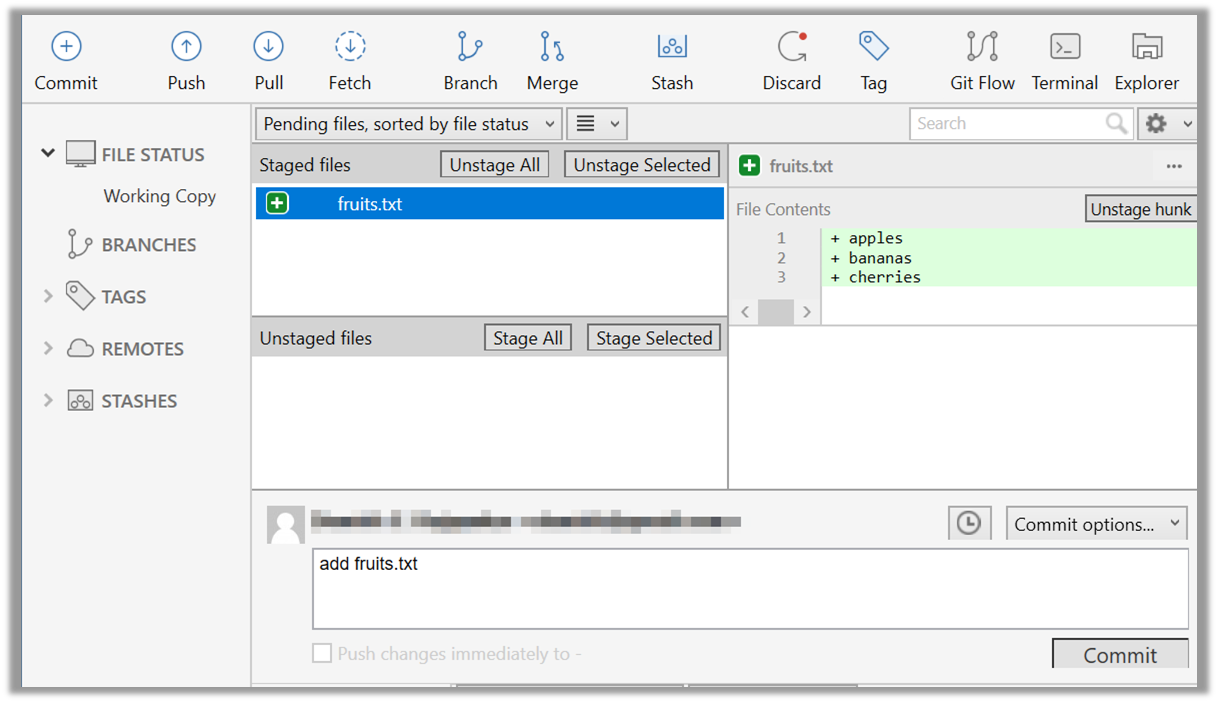
Use the commit command to commit. The -m switch is used to specify the commit message.
git commit -m "Add fruits.txt"
You can use the log command to see the commit history.
git log
commit 8fd30a6910efb28bb258cd01be93e481caeab846
Author: … < … @... >
Date: Wed Jul 5 16:06:28 2017 +0800
Add fruits.txt
Note the existence of something called the master branch. Git allows you to have multiple branches (i.e. it is a way to evolve the content in parallel) and Git auto-creates a branch named master on which the commits go on by default.
5. Do a few more commits.
Make some changes to
fruits.txt(e.g. add some text and delete some text). Stage the changes, and commit the changes using the same steps you followed before. You should end up with something like this.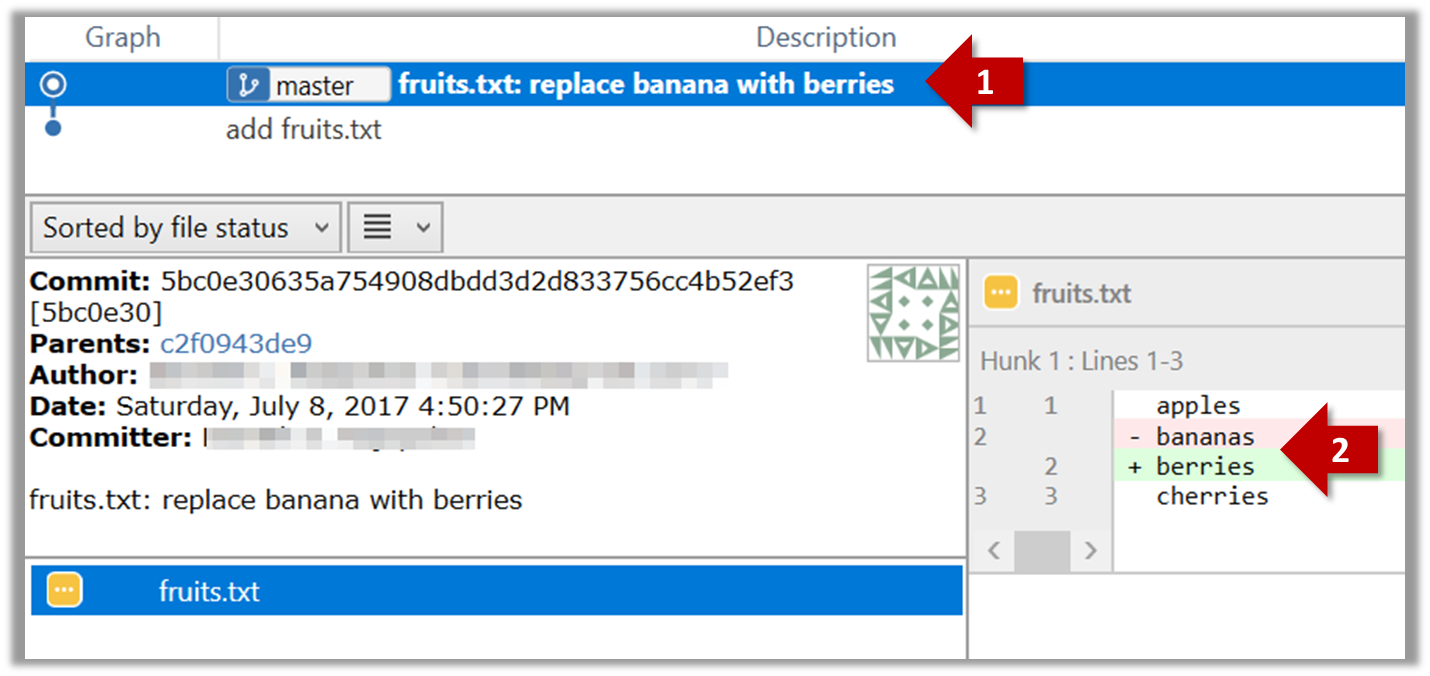
Next, add two more files
colors.txtandshapes.txtto the same working directory. Add a third commit to record the current state of the working directory.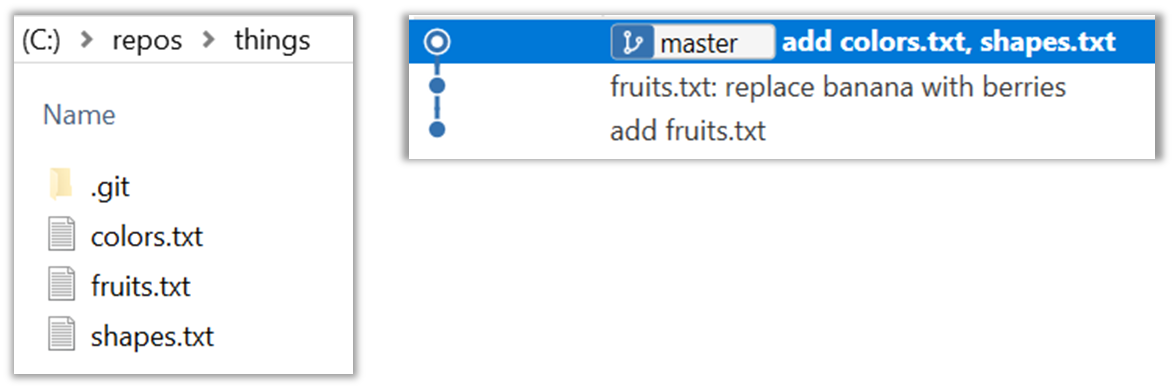
6. See the revision graph: Note how commits form a path-like structure aka the revision tree/graph. In the revision graph, each commit is shown as linked to its 'parent' commit (i.e., the commit before it).
To see the revision graph, click on the History item on the menu on the right edge of SourceTree.
The gitk command opens a rudimentary graphical view of the revision graph.
Guidance for the item(s) below:
Previously, you learned how to save revision history in your local repository, in the form of commits. Next, let us use how to make use of that history.
Can tag commits using Git
Each Git commit is uniquely identified by a hash e.g., d670460b4b4aece5915caf5c68d12f560a9fe3e4. As you can imagine, using such an identifier is not very convenient for our day-to-day use. As a solution, Git allows adding a more human-readable tag to a commit e.g., v1.0-beta.
Here's how you can tag a commit in a local repo (e.g. in the samplerepo-things repo):
Right-click on the commit (in the graphical revision graph) you want to tag and choose Tag….
Specify the tag name e.g. v1.0 and click Add Tag.
The added tag will appear in the revision graph view.
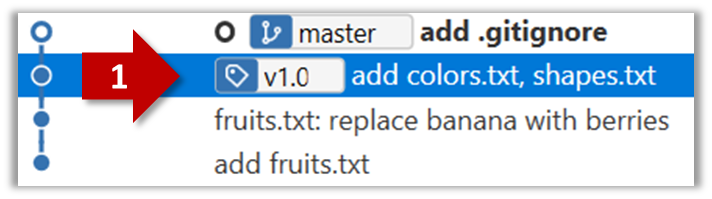
To add a tag to the current commit as v1.0,
git tag –a v1.0
To view tags
git tag
To learn how to add a tag to a past commit, go to the ‘Git Basics – Tagging’ page of the git-scm book and refer the ‘Tagging Later’ section.
Remember to push tags to the repo. A normal push does not include tags.
# push a specific tag
git push origin v1.0b
# push all tags
git push origin --tags
After adding a tag to a commit, you can use the tag to refer to that commit, as an alternative to using the hash.
Tags are different from commit messages, in purpose and in form. A commit message is a description of the commit that is part of the commit itself. A tags is a short name for a commit, which exists as a separate entity that points to a commit.
Can compare git revisions
Git can show you what changed in each commit.
To see which files changed in a commit, click on the commit. To see what changed in a specific file in that commit, click on the file name.
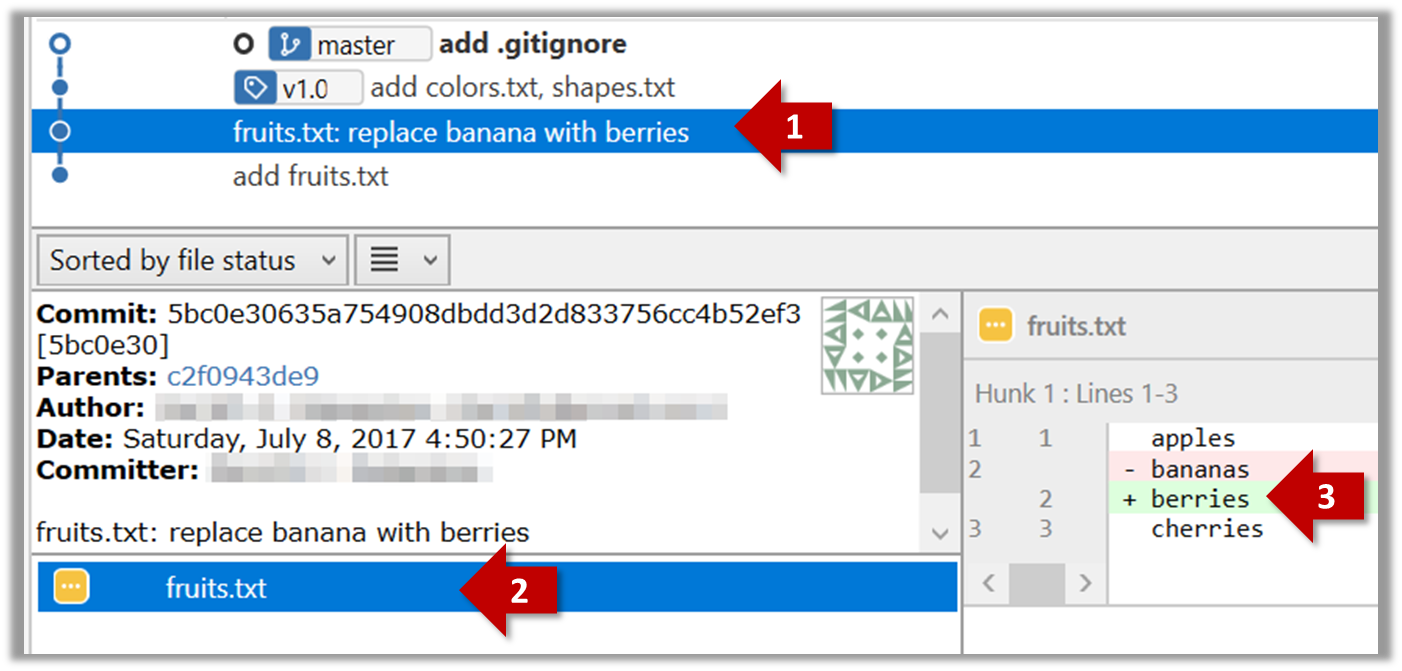
git show < part-of-commit-hash >
Example:
git show 251b4cf
commit 5bc0e30635a754908dbdd3d2d833756cc4b52ef3
Author: … < … >
Date: Sat Jul 8 16:50:27 2017 +0800
fruits.txt: replace banana with berries
diff --git a/fruits.txt b/fruits.txt
index 15b57f7..17f4528 100644
--- a/fruits.txt
+++ b/fruits.txt
@@ -1,3 +1,3 @@
apples
-bananas
+berries
cherries
Git can also show you the difference between two points in the history of the repo.
Select the two points you want to compare using Ctrl+Click. The differences between the two selected versions will show up in the bottom half of SourceTree, as shown in the screenshot below.
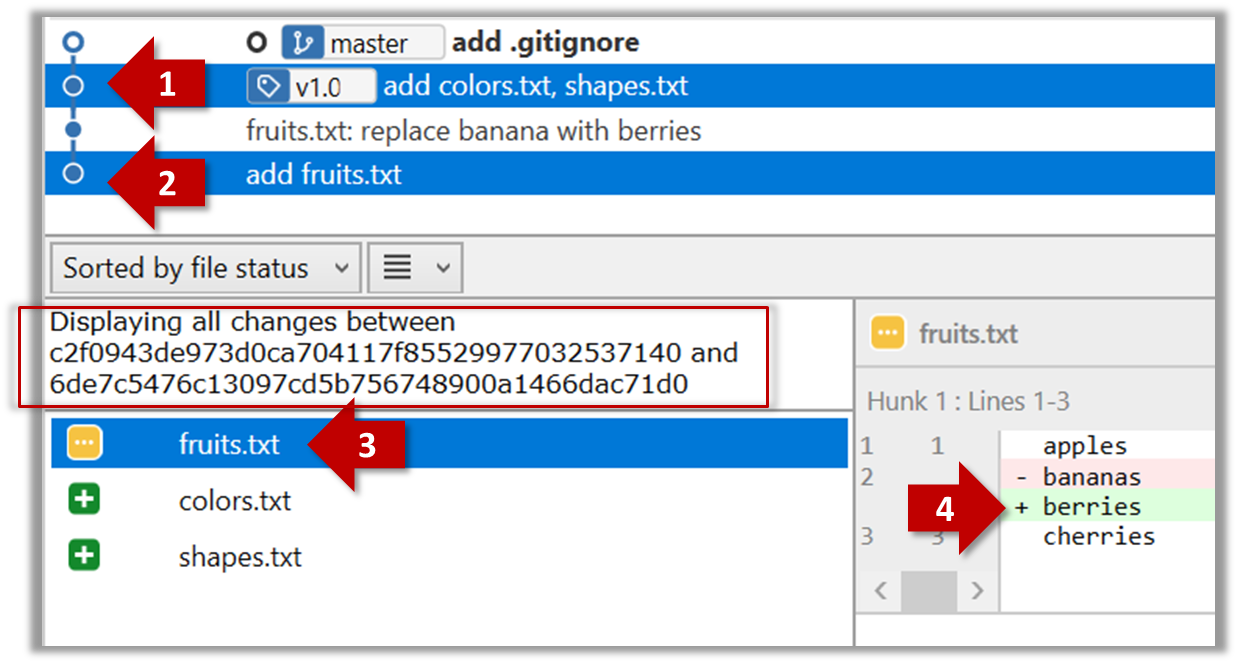
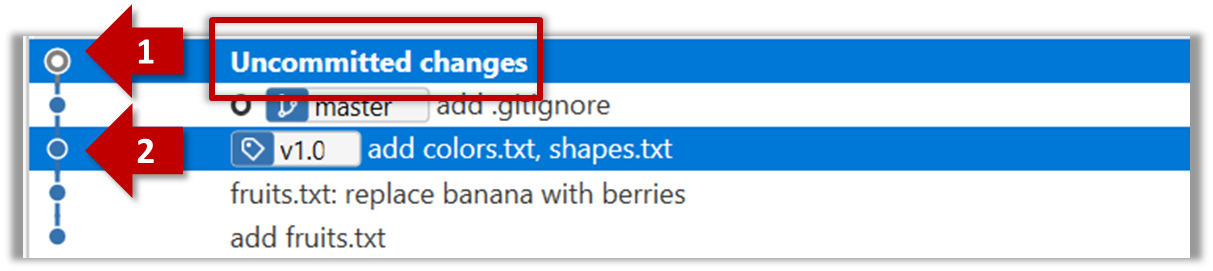
The same method can be used to compare the current state of the working directory (which might have uncommitted changes) to a point in the history.
The diff command can be used to view the differences between two points of the history.
git diff: shows the changes (uncommitted) since the last commit.git diff 0023cdd..fcd6199: shows the changes between the points indicated by commit hashes.
Note that when using a commit hash in a Git command, you can use only the first few characters (e.g., first 7-10 chars) as that's usually enough for Git to locate the commit.git diff v1.0..HEAD: shows changes that happened from the commit tagged asv1.0to the most recent commit.
Can load a specific version of a Git repo
Git can load a specific version of the history to the working directory. Note that if you have uncommitted changes in the working directory, you need to stash them first to prevent them from being overwritten.
Double-click the commit you want to load to the working directory, or right-click on that commit and choose Checkout....
Click OK to the warning about ‘detached HEAD’ (similar to below).
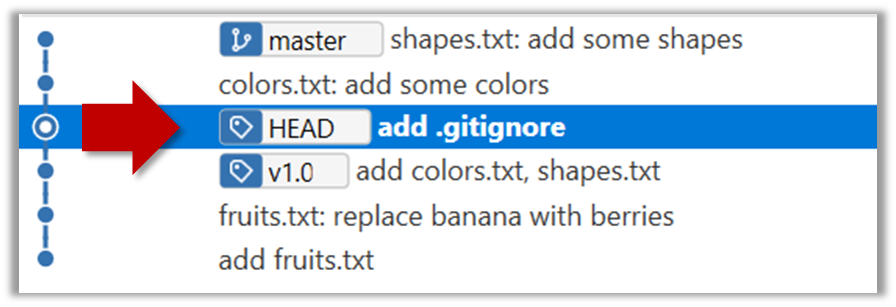
The specified version is now loaded to the working folder, as indicated by the HEAD label. HEAD is a reference to the currently checked out commit.
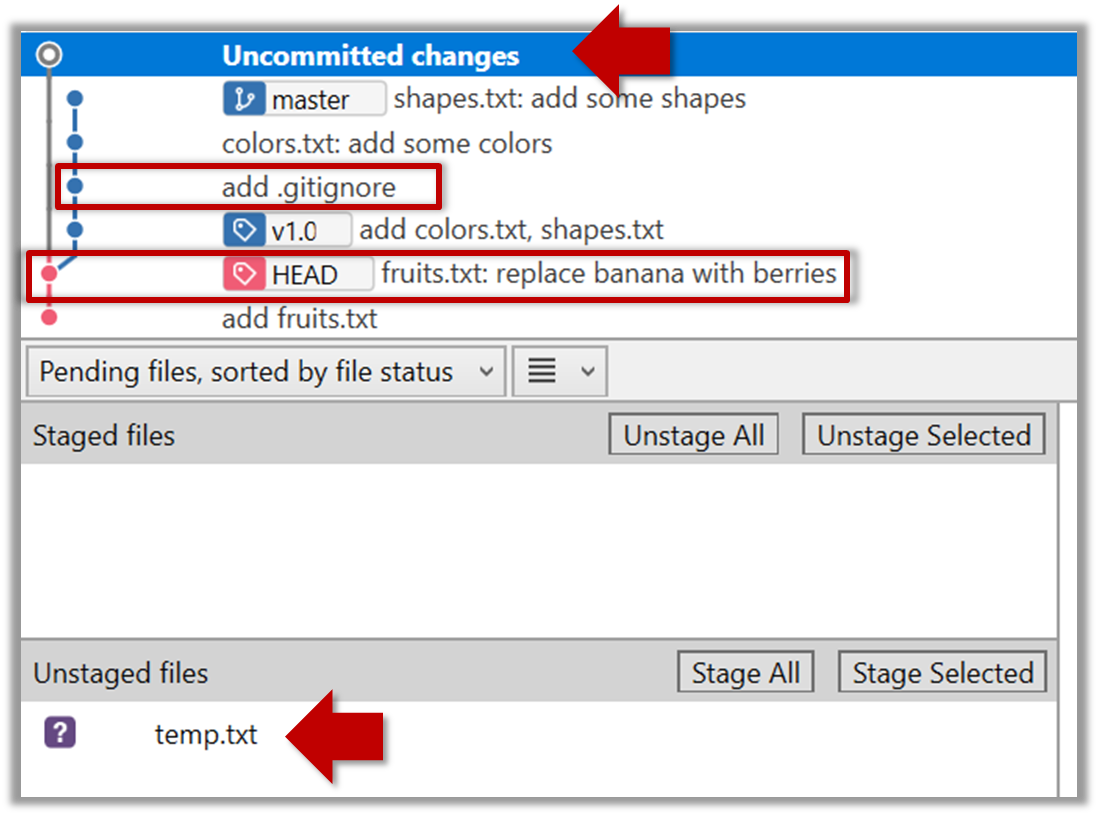
If you checkout a commit that comes before the commit in which you added the .gitignore file, Git will now show ignored files as ‘unstaged modifications’ because at that stage Git hasn’t been told to ignore those files.
To go back to the latest commit, double-click it.
Use the checkout <commit-identifier> command to change the working directory to the state it was in at a specific past commit.
git checkout v1.0: loads the state as at commit taggedv1.0git checkout 0023cdd: loads the state as at commit with the hash0023cddgit checkout HEAD~2: loads the state that is 2 commits behind the most recent commit
For now, you can ignore the warning about ‘detached HEAD’.