Testing: Operating a system or component under specified conditions, observing or recording the results, and making an evaluation of some aspect of the system or component. –- source: IEEE
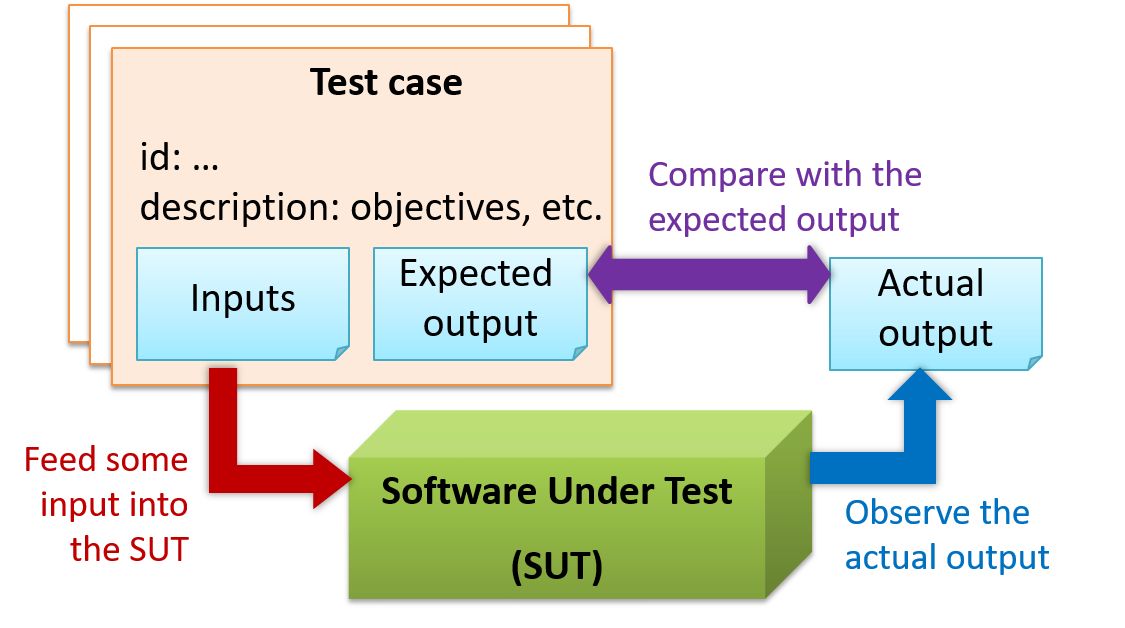
When testing, you execute a set of test cases. A test case specifies how to perform a test. At a minimum, it specifies the input to the software under test (SUT) and the expected behavior.
Example: A minimal test case for testing a browser:
- Input – Start the browser using a blank page (vertical scrollbar disabled). Then, load
longfile.htmllocated in thetest datafolder. - Expected behavior – The scrollbar should be automatically enabled upon loading
longfile.html.
Test cases can be determined based on the specification, reviewing similar existing systems, or comparing to the past behavior of the SUT.
For each test case you should do the following:
- Feed the input to the SUT
- Observe the actual output
- Compare actual output with the expected output
A test case failure is a mismatch between the expected behavior and the actual behavior. A failure indicates a potential defect (or a bug), unless the error is in the test case itself.
Example: In the browser example above, a test case failure is implied if the scrollbar remains disabled after loading longfile.html. The defect/bug causing that failure could be an uninitialized variable.
Delaying testing until the full product is complete has a number of disadvantages:
- Locating the cause of a test case failure is difficult due to a large search space; in a large system, the search space could be millions of lines of code, written by hundreds of developers! The failure may also be due to multiple inter-related bugs.
- Fixing a bug found during such testing could result in major rework, especially if the bug originated from the design or during requirements specification i.e. a faulty design or faulty requirements.
- One bug might 'hide' other bugs, which could emerge only after the first bug is fixed.
- The delivery may have to be delayed if too many bugs are found during testing.
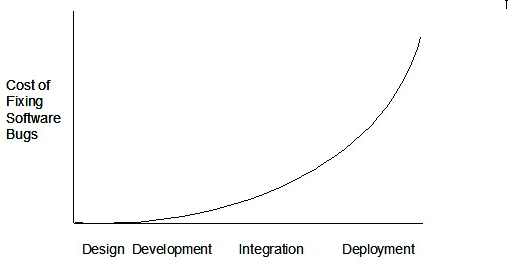
Therefore, it is better to do early testing, as hinted by the popular rule of thumb given below, also illustrated by the graph below it.
The earlier a bug is found, the easier and cheaper to have it fixed.
Such early testing of partially developed software is usually, and by necessity, done by the developers themselves i.e. developer testing.
JUnit is a tool for automated testing of Java programs. Similar tools are available for other languages and for automating different types of testing.
This is an automated test for a Payroll class, written using JUnit libraries.
@Test
public void testTotalSalary() {
Payroll p = new Payroll();
// test case 1
p.setEmployees(new String[]{"E001", "E002"});
assertEquals(6400, p.totalSalary());
// test case 2
p.setEmployees(new String[]{"E001"});
assertEquals(2300, p.totalSalary());
// more tests...
}
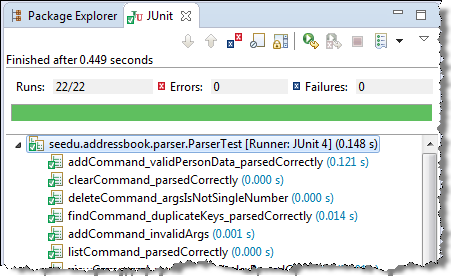
Most modern IDEs have integrated support for testing tools. The figure below shows the JUnit output when running some JUnit tests using the Eclipse IDE.
If a software product has a GUI (Graphical User Interface) component, all product-level testing (i.e. the types of testing mentioned above) need to be done using the GUI. However, testing the GUI is much harder than testing the CLI (Command Line Interface) or API, for the following reasons:
- Most GUIs can support a large number of different operations, many of which can be performed in any arbitrary order.
- GUI operations are more difficult to automate than API testing. Reliably automating GUI operations and automatically verifying whether the GUI behaves as expected is harder than calling an operation and comparing its return value with an expected value. Therefore, automated regression testing of GUIs is rather difficult.
- The appearance of a GUI (and sometimes even behavior) can be different across platforms and even environments. For example, a GUI can behave differently based on whether it is minimized or maximized, in focus or out of focus, and in a high resolution display or a low resolution display.
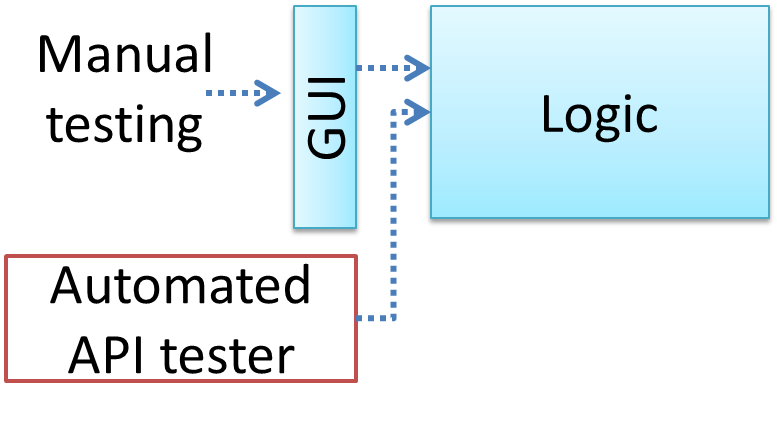
Moving as much logic as possible out of the GUI can make GUI testing easier. That way, you can bypass the GUI to test the rest of the system using automated API testing. While this still requires the GUI to be tested, the number of such test cases can be reduced as most of the system will have been tested using automated API testing.
There are testing tools that can automate GUI testing.
Some tools used for automated GUI testing:
TestFX can do automated testing of JavaFX GUIs
Visual Studio supports the ‘record replay’ type of GUI test automation.
Selenium can be used to automate testing of web application UIs
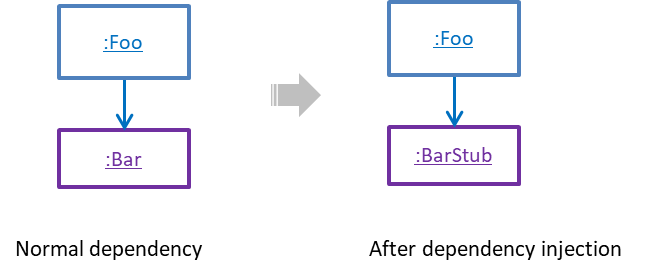
Dependency injection is the process of 'injecting' objects to replace current dependencies with a different object. This is often used to inject stubs to isolate the from its so that it can be tested in isolation.
A Foo object normally depends on a Bar object, but you can inject a BarStub object so that the Foo object no longer depends on a Bar object. Now you can test the Foo object in isolation from the Bar object.